2 Application to Handwritten Letter Data
We now examine Optical Recognition of Handwritten Digits Data Set, which contains 5,620 samples of handwritten digits 0..9. You can use these links to download the training data and test data, and then we’ll load them into R:
digits_train = read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tra", header = FALSE)
digits_train = data.frame(x = digits_train[,-1], y = as.factor(digits_train[,65]))
digits_test = read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tes", header = FALSE)
digits_test = data.frame(x = digits_test[,-1], y = as.factor(digits_test[,65]))Let’s take a look at the dimensions of this dataset:
## [1] 3823 65## [1] 1797 65This data set consists of preprocessed images of handwriting samples gathered from 43 different people. Each image was converted into an 8x8 matrix (64 pixels), which was then flattened into a vector of 64 numeric values. The final column contains the class label for each digit.
The training and test sets consist of 3,823 and 1,797 observations respectively. Let’s see what one of these digits looks like:
m = matrix(unlist(digits_train[1,-1]),8,8)
image(m, axes = FALSE, col = grey(seq(0, 1, length = 256)))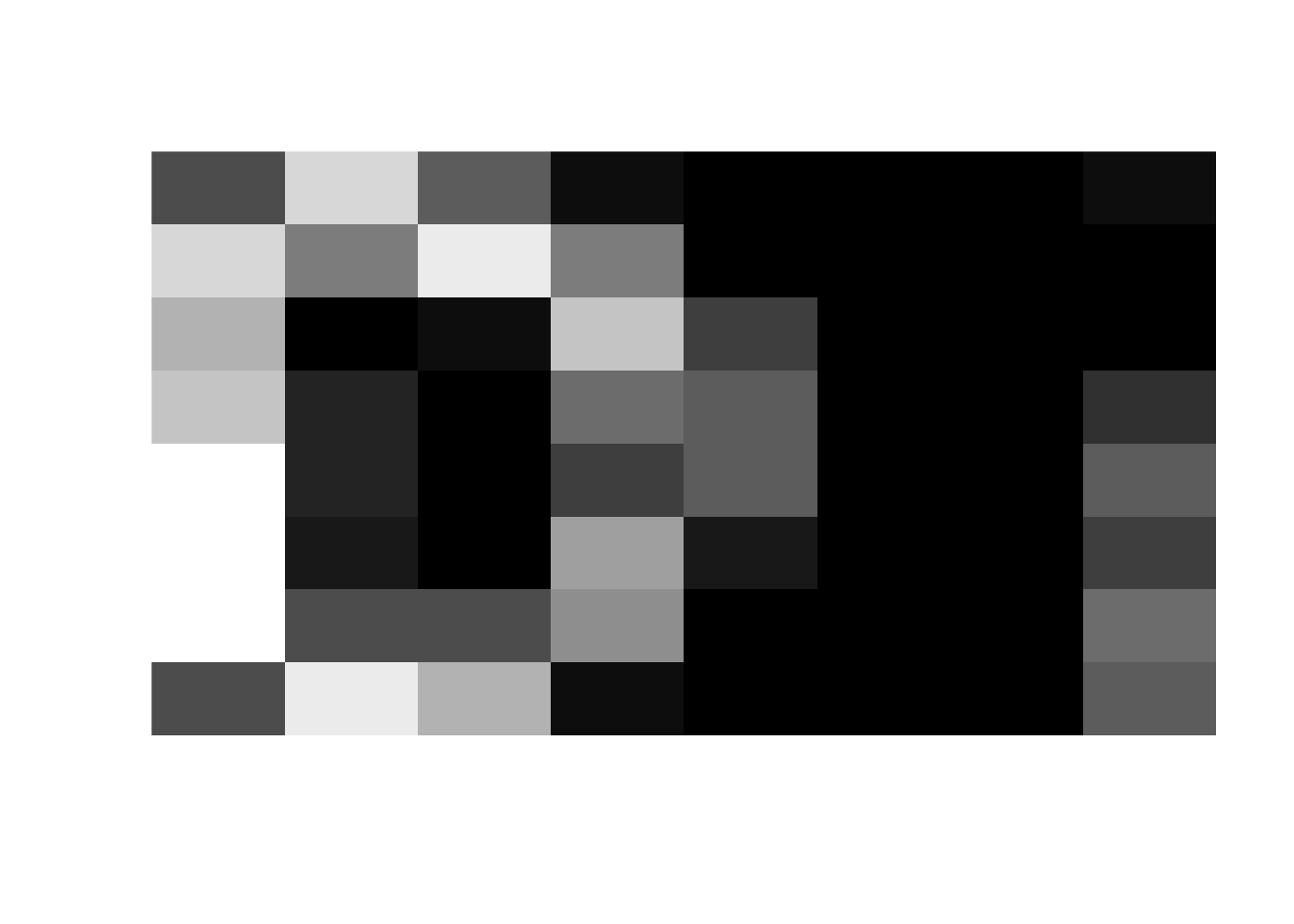
That’s a pretty messy digit. Let’s peek at the true class:
## [1] 0
## Levels: 0 1 2 3 4 5 6 7 8 9Phew, looks like our SVM has its work cut out for it! Let’s start with a linear kernel to see how we do:
digits_svm = svm(y~., data = digits_train, kernel = "linear", cost = 10, scale = FALSE)
table(digits_svm$fitted, digits_train$y)##
## 0 1 2 3 4 5 6 7 8 9
## 0 376 0 0 0 0 0 0 0 0 0
## 1 0 389 0 0 0 0 0 0 0 0
## 2 0 0 380 0 0 0 0 0 0 0
## 3 0 0 0 389 0 0 0 0 0 0
## 4 0 0 0 0 387 0 0 0 0 0
## 5 0 0 0 0 0 376 0 0 0 0
## 6 0 0 0 0 0 0 377 0 0 0
## 7 0 0 0 0 0 0 0 387 0 0
## 8 0 0 0 0 0 0 0 0 380 0
## 9 0 0 0 0 0 0 0 0 0 382We see that there are no training errors. In fact, this is not surprising, because the large number of variables relative to the number of observations implies that it is easy to find hyperplanes that fully separate the classes. We are most interested not in the support vector classifier’s performance on the training observations, but rather its performance on the test observations:
##
## pred 0 1 2 3 4 5 6 7 8 9
## 0 178 0 0 1 0 0 0 0 0 0
## 1 0 181 5 0 0 0 0 0 0 0
## 2 0 0 170 3 0 1 0 0 0 0
## 3 0 0 0 176 0 0 0 0 0 0
## 4 0 0 0 0 180 0 1 1 1 0
## 5 0 0 0 2 0 180 0 3 1 1
## 6 0 1 2 0 0 0 179 0 0 0
## 7 0 0 0 1 0 0 0 169 0 0
## 8 0 0 0 0 1 0 1 0 169 4
## 9 0 0 0 0 0 1 0 6 3 175We see that using cost = 10 yields just 40 test set errors on this data. Now try using the tune() function to select an optimal value for cost, and refit the model using that value. Consider values in the range 0.01 to 100: